Presto is a popular, open source, distributed SQL engine that enables organizations to run interactive analytic queries on multiple data sources at a large scale. Caching is a typical optimization technique for improving Presto query performance. It provides significant performance and efficiency improvements for Presto platforms.
Caching avoids expensive disk or network trips to refetch data by storing frequently accessed data in memory or on fast local storage, speeding up overall query execution. In this article, we provide a deep dive into Presto’s caching mechanisms and how you can use them to boost query speeds and reduce costs.
Benefits of caching
Caching provides three key advantages. By implementing caching in Presto, you can:
- Boost query performance. Caching frequently accessed data allows Presto to retrieve results from faster and closer caches rather than scanning slower storage. For repetitive analytical queries, this can improve query speeds by orders of magnitude, reducing overall latency. By accelerating query execution, caching enables interactive querying and faster time-to-insight.
- Reduce infrastructure costs. Caching reduces the volume of data read from remote storage systems like S3, resulting in lower egress charges and charges for storage API requests. For data stored in the cloud, caching minimizes repetitive retrieval of data over the network. This provides substantial cost savings, especially for large datasets.
- Minimize network overhead. By reducing unnecessary data transfer between Presto components and remote storage, caching alleviates network congestion. Local caching prevents bottlenecking of network links between distributed Presto workers. It also reduces load and bandwidth usage on connections to external data sources.
Overall, caching can boost performance and efficiency of Presto queries, providing significant value and ROI for Presto-based analytics platforms.
Different types of caching in Presto
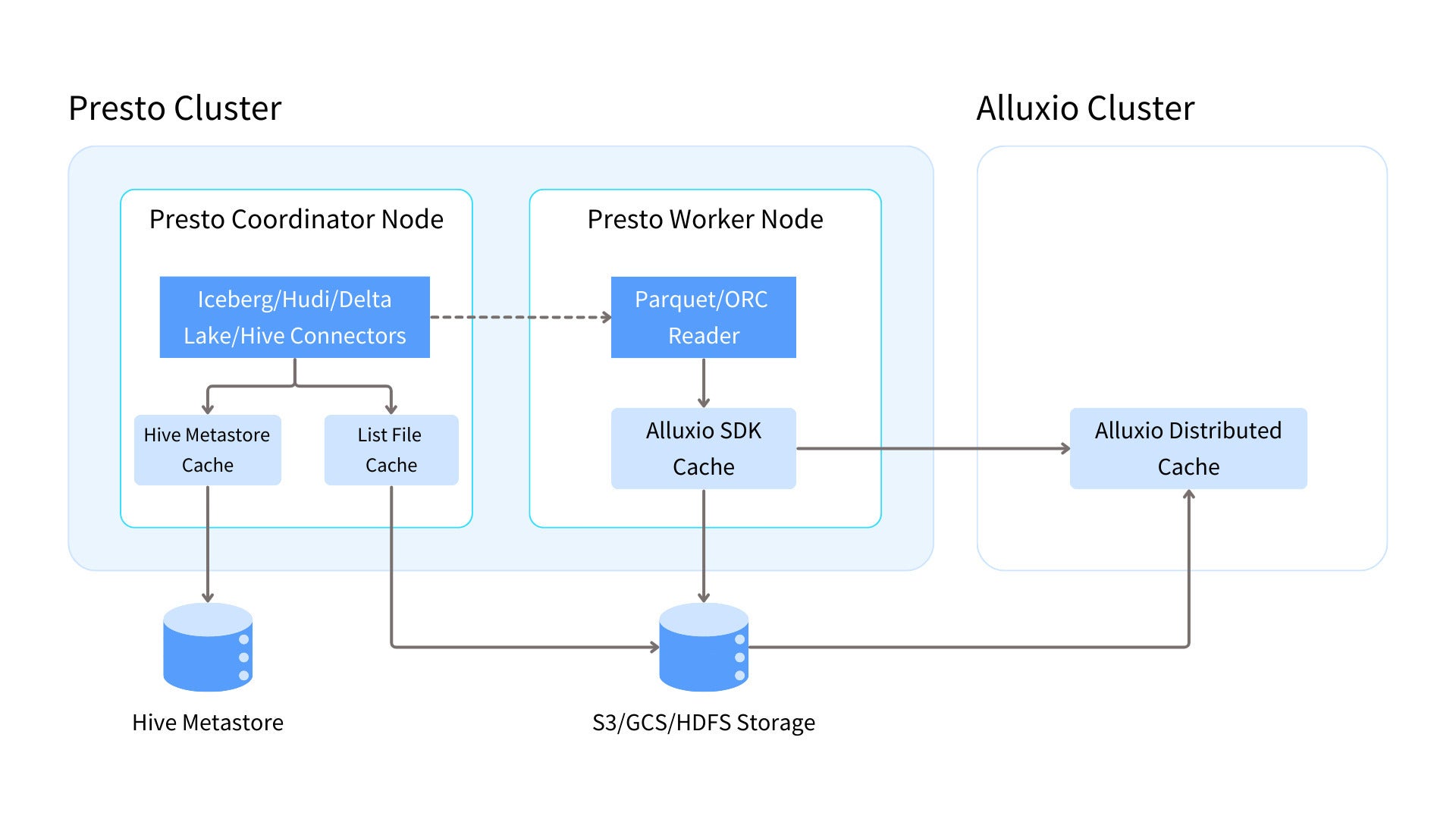
There are two types of caches in Presto, the built-in cache and third-party caches. The built-in cache includes the metastore cache, file list cache, and Alluxio SDK cache. It uses the memory and SSD resources of the Presto cluster, running within the same process as Presto for optimal performance.
The main benefits of built-in caches are very low latency and no network overhead because data is cached locally within the Presto cluster. However, built-in cache capacity is constrained by worker node resources.
Third-party caches, such as the Alluxio distributed cache, are independently deployable and offer better scalability and increased cache capacity. They are particularly advantageous for large-scale analytics workloads, cross-region/cloud deployments, and reducing API and egress costs for cloud storage.
 Alluxio
AlluxioThe diagram above and table below summarizes the different cache types, their corresponding resource types, locations.
|
Type of cache |
Cache location |
Resource type |
|
Metastore cache |
Presto coordinator |
Memory |
|
List file cache |
Presto coordinator |
Memory |
|
Alluxio SDK cache |
Presto workers |
Memory/SSD |
|
Alluxio distributed cache |
Alluxio workers |
Memory/SSD/HDD |
None of Presto’s caches are enabled by default. You will need to modify Presto’s configuration to activate them. We will explain the different caching types in more detail and how to enable them via configuration properties in the following sections.
Metastore cache
Presto’s metastore cache stores Hive metastore query results in memory for faster access. This reduces planning time and metastore requests.
The metastore cache is highly beneficial when the Hive metastore is overloaded. For large partitioned tables, the cache stores partition metadata locally, enabling faster access and fewer repeated queries. This decreases the overall load on the Hive metastore.
To enable metastore cache, use the following settings:
hive.partition-versioning-enabled=true hive.metastore-cache-scope=ALL hive.metastore-cache-ttl=1d hive.metastore-refresh-interval=1d hive.metastore-cache-maximum-size=10000000
Note that, if tables are frequently updated, you should configure a shorter TTL or refresh interval for the metastore versioned cache. A shorter cache refresh interval ensures only current metadata is stored, reducing the risk of outdated metadata in query execution. This prevents Presto from using stale data.
List file status cache
The list file cache stores file paths and attributes to avoid repeated retrievals from the namenode or object store.
The list file cache substantially improves query latency when the HDFS namenode is overloaded or object stores have poor file listing performance. List file calls can bottleneck HDFS, overwhelming the name node, and increase costs for S3 storage. When the list file status cache is enabled, the Presto coordinator caches file lists in memory for faster access to frequently used data, reducing lengthy remote listFile calls.
To configure list file status caching, use the following settings:
hive.file-status-cache-expire-time=1h hive.file-status-cache-size=10000000 hive.file-status-cache-tables=*
Note that the list file status cache can be applied only to sealed directories, as Presto skips caching open partitions to ensure data freshness.
Alluxio SDK cache (native)
The Alluxio SDK cache is a Presto built-in cache that reduces table scan latency. Because Presto is a storage-agnostic engine, its performance is often bottlenecked by storage. Caching data locally on Presto worker SSDs enables fast query access and execution. By minimizing repeated network requests, the Alluxio cache also reduces cloud egress fees and storage API costs for remote data.
The Alluxio SDK cache is particularly beneficial for querying remote data like cross-region or hybrid cloud object stores. This significantly decreases query latency and associated cloud storage egress costs and API costs.
Enable the Alluxio SDK cache with the settings below:
cache.enabled=true cache.type=ALLUXIO cache.base-directory=file:///tmp/alluxio cache.alluxio.max-cache-size=100MB
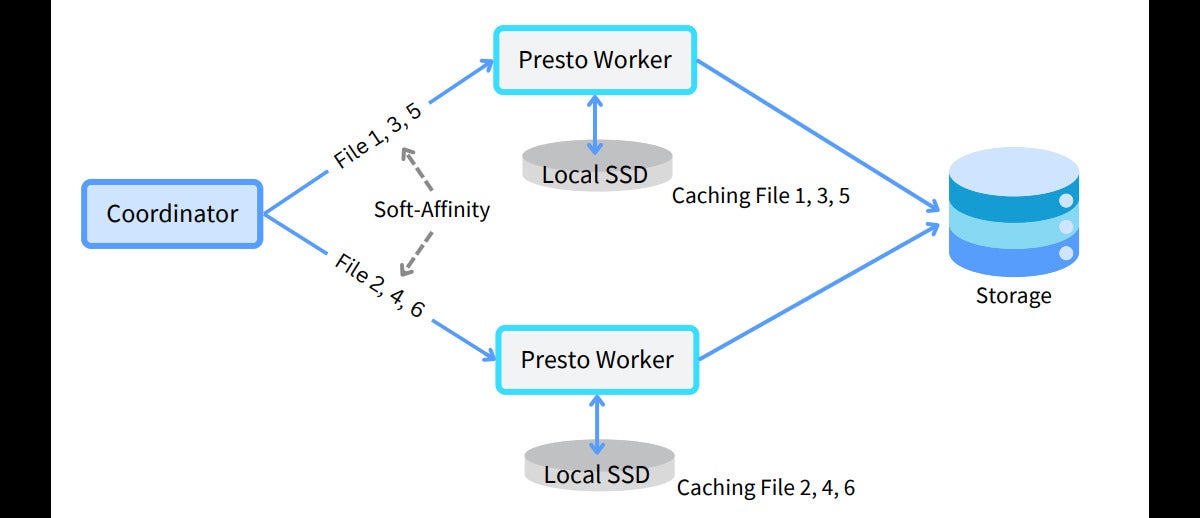
To achieve the best cache hit rate, change the node selection strategy to soft affinity:
hive.node-selection-strategy=SOFT_AFFINITY
 Alluxio
AlluxioThe diagram above shows the soft-affinity node selection architecture. Soft-affinity scheduling attempts to send requests to workers based on file paths, maximizing cache hits by locating data in worker caches. Soft affinity is “soft” because it is not a strict rule—if the preferred worker is busy, the split is sent to another available worker rather than waiting.
If you encounter errors such as “Unsupported Under FileSystem,” download the latest Alluxio client JAR from the Maven repository and place it in the {$presto_root_path}/plugin/hive-hadoop2/ directory.
You can view the full documentation here.
Alluxio distributed cache (third-party)
If Presto memory or storage is insufficient for large datasets, using a third-party caching solution provides expansive caching for frequent data access. A third-party cache can deliver several optimizations for Presto:
- Improve performance by reducing I/O latency
- Accelerate queries on remote cross-datacenter or cloud data storage
- Provide a shared cache between Presto workers, clusters, and other engines like Apache Spark
- Enables resilient caching for cost savings on spot instances
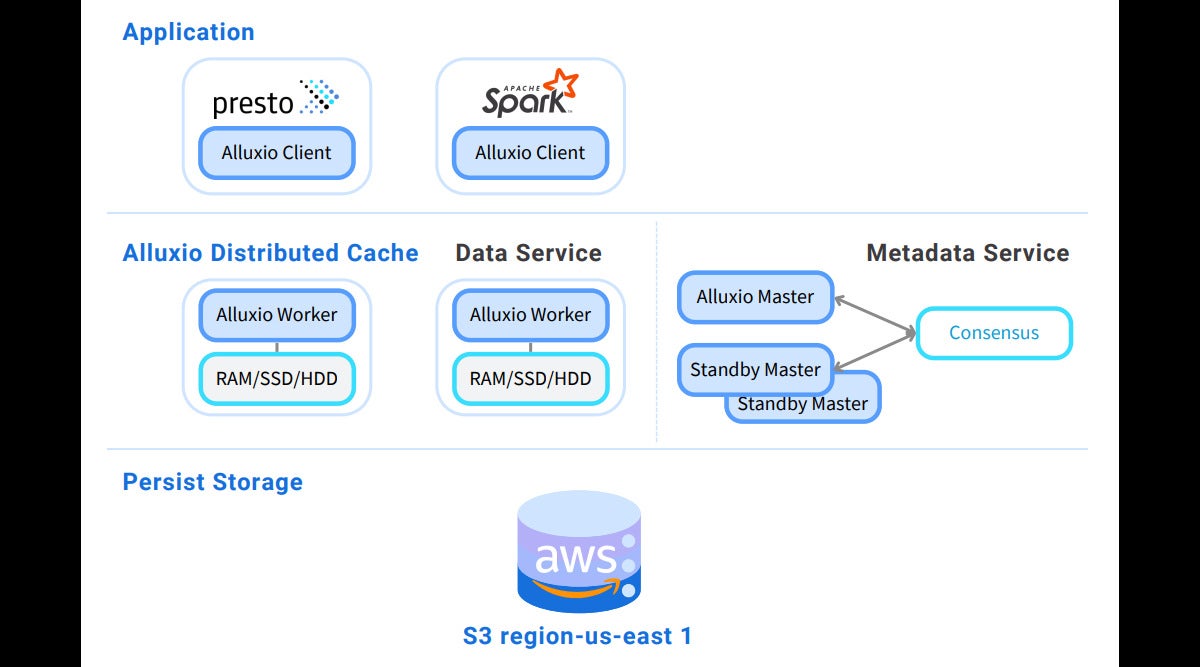
The Alluxio distributed cache is one example of a third-party cache. As you can see in the diagram below, the Alluxio distributed cache is deployed between Presto and storage like S3. Alluxio uses a master-worker architecture where the master manages metadata and workers manage cached data on local storage (memory, SSD, HDD). On a cache hit, the Alluxio worker returns data to the Presto worker. Otherwise, the Alluxio worker retrieves data from persistent storage and caches data for future use. Presto workers process the cached data and the coordinator returns results to the user.
 Alluxio
AlluxioHere are the steps to deploy Alluxio distributed caching with Presto.
1. Distribute the Alluxio client JAR to all Presto servers
In order for Presto to be able to communicate with the Alluxio servers, the Alluxio client jar must be in the classpath of Presto servers. Put the Alluxio client JAR /<PATH_TO_ALLUXIO>/client/alluxio-2.9.3-client.jar into the directory ${PRESTO_HOME}/plugin/hive-hadoop2/ on all Presto servers. Restart the Presto workers and coordinator using the command below:
$ ${PRESTO_HOME}/bin/launcher restart
2. Add Alluxio Configurations to Presto’s HDFS configuration files
You can add Alluxio’s properties to the HDFS configuration files such as core-site.xml and hdfs-site.xml, and then use the Presto property hive.config.resources in the file ${PRESTO_HOME}/etc/catalog/hive.properties to point to the locations of HDFS configuration files on every Presto worker.
hive.config.resources=/<PATH_TO_CONF>/core-site.xml,/<PATH_TO_CONF>/hdfs-site.xml
Then, add the property to the HDFS core-site.xml configuration, which is linked by hive.config.resources in Presto’s property.
<configuration> <property> <name>alluxio.master.rpc.addresses</name> <value>master_hostname_1:19998,master_hostname_2:19998,master_hostname_3:19998</value> </property> </configuration>
Based on the configuration above, Presto is able to locate the Alluxio cluster and forward the data access to it.
To learn more about Alluxio distributed cache for Presto, follow this documentation.
Choosing the right cache for your use case
Caching is a powerful way to improve Presto query performance. In this article, we have introduced different caching mechanisms in Presto, including the metastore cache, the list file status cache, the Alluxio SDK cache, and the Alluxio distributed cache. As summarized in the table below, you can use these caches to accelerate data access based on your use case.
|
Type of cache |
When to use |
|
Metastore cache |
Slow planning time |
|
List file status cache |
Overloaded HDFS namenode |
|
Alluxio SDK cache |
Slow or unstable external storage |
|
Alluxio distributed cache |
Cross-region, multicloud, hybrid cloud |
The Presto and Alluxio open-source communities work continuously to improve the existing caching features and to develop new capabilities to enhance query speeds, optimize efficiency, and improve the system’s scalability and reliability.
References:
Beinan Wang is senior staff engineer at Alluxio. He has 15 years of experience in performance optimization and large-scale data processing. He is a PrestoDB committer and contributes to the Trino project. He previously led Twitter’s Presto team. Beinen earned his Ph.D. in computer engineering from Syracuse University, specializing in distributed systems.
Hope Wang is developer advocate at Alluxio. She has a decade of experience in data, AI, and cloud. An open source contributor to Presto, Trino, and Alluxio, she also holds AWS Certified Solutions Architect – Professional status. Hope earned a BS in computer science, a BA in economics, and an MEng in software engineering from Peking University and an MBA from USC.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
Copyright © 2023 IDG Communications, Inc.











{kind=link}