The article, Machine learning for Java developers: Algorithms for machine learning, introduced setting up a machine learning algorithm and developing a prediction function in Java. Readers learned the inner workings of a machine learning algorithm and walked through the process of developing and training a model. This article picks up where that one left off. You’ll get a quick introduction to Weka, a machine learning framework for Java. Then, you’ll see how to set up a machine learning data pipeline, with a step-by-step process for taking your machine learning model from development into production. We’ll also briefly discuss how to use Docker containers and REST to deploy a trained ML model in a Java-based production environment.
What to expect from this article
Deploying a machine learning model is not the same as developing one. These are different parts of the software development lifecycle, and often implemented by different teams. Developing a machine learning model requires understanding the underlying data and having a good grasp of mathematics and statistics. Deploying a machine learning model in production is typically a job for someone with both software engineering and operations experience.
This article is about how to make a machine learning model available in a highly scalable production environment. It is assumed that you have some development experience and a basic understanding of machine learning models and algorithms; otherwise, you may want to start by reading Machine learning for Java developers: Algorithms for machine learning.
Let’s start with a quick refresher on supervised learning, including the example application we’ll use to train, deploy, and process a machine learning model for use in production.
Supervised machine learning: A refresher
A simple, supervised machine learning model will illustrate the ML deployment process. The model shown in Figure 1 can be used to predict the expected sale price of a house.
 IDG
IDGFigure 1. Trained supervised machine learning model for sale price prediction.
Recall that a machine learning model is a function with internal, learnable parameters that map inputs to outputs. In the above diagram, a linear regression function, hθ(x), is used to predict the sale price for a house based on a variety of features. The x variables of the function represent the input data. The θ (theta) variables represents the internal, learnable model parameters.
To predict the sale price of a house, you must first create an input data array of x variables. This array contains features such as the size of the lot or the number of rooms in a house. This array is called the feature vector.
Because most machine learning functions require a numerical representation of features, you will likely have to perform some data transformations in order to build a feature vector. For instance, a feature specifying the location of the garage could include labels such as “attached to home” or “built-in,” which have to be mapped to numerical values. When you execute the house-price prediction, the machine learning function will be applied with this input feature vector as well as the internal, trained model parameters. The function’s output is the estimated house price. This output is called a label.
Training the model
Internal, learnable model parameters (θ) are the part of the model that is learned from training data. The learnable parameters will be set during the training process. A supervised machine learning model like the one shown below has to be trained in order to make useful predictions.
 IDG
IDGFigure 2. An untrained supervised machine learning model
Typically, the training process starts with an untrained model where all the learnable parameters are set with an initial value such as zero. The model consumes data about various house features along with real house prices. Gradually, it identifies correlations between house features and house prices, as well as the weight of these relationships. The model adjusts its internal, learnable model parameters and uses them to make predictions.
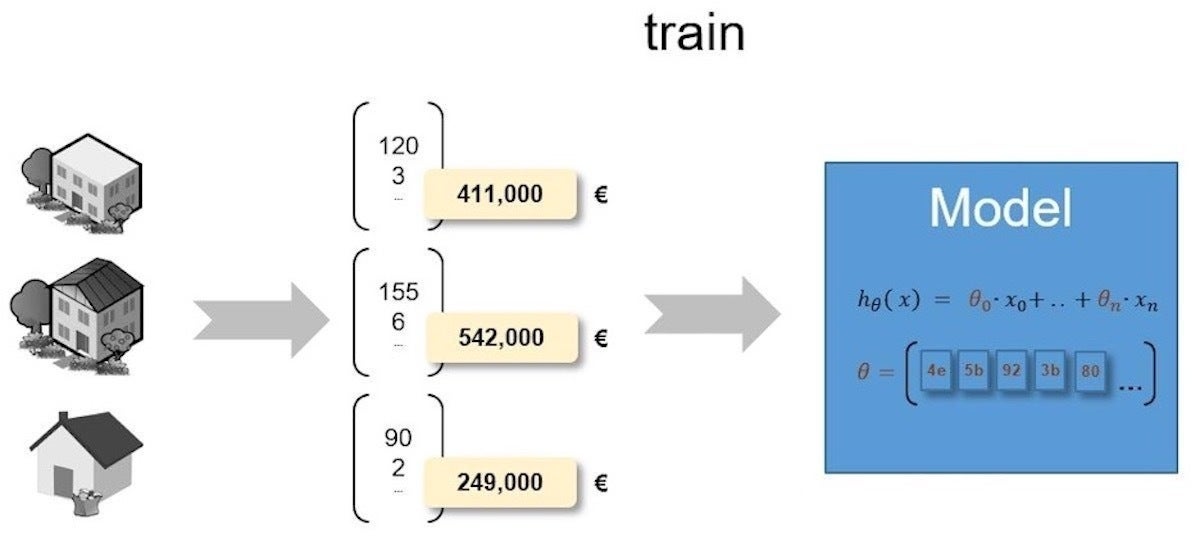 IDG
IDGFigure 3. A trained supervised machine learning model
After the training process, the model will be able to estimate the sale price of a house by assessing its features.
Machine learning algorithms in Java code
The HousePriceModel provides two methods. One of them implements the learning algorithm to train (or fit) the model. The other method is used for predictions.
 IDG
IDGFigure 4. Two methods in a machine learning model
The fit() method
The fit() method is used to train the model. It consumes house features as well as house-sale prices as input parameters but returns nothing. This method requires the correct “answer” to be able to adjust its internal model parameters. Using housing listings paired with sale prices, the learning algorithm looks for patterns in the training data. From these, it produces model parameters that generalize from those patterns. As the input data becomes more accurate, the model’s internal parameters are adjusted.
Listing 1. The fit() method is used to train a machine learning model
// load training data
// ...
// e.g. [{MSSubClass=60.0, LotFrontage=65.0, ...}, {MSSubClass=20.0, ...}]
List<Map<String, Double>> houses = ...;
// e.g. [208500.0, 181500.0, 223500.0, 140000.0, 250000.0, ...]
List<Double> prices = ...;
// create and train the model
var model = new HousePriceModel();
model.fit(houses, prices);
Note that the house features are double typed in the code. This is because the machine learning algorithm used to implement the fit() method requires numbers as input. All house features must be represented numerically so that they can be used as x parameters in the linear regression formula, as shown here:
hθ(x) = θ0 * x0 + ... + θn * xn
The trained house price prediction model could look like what you see below:
price = -490130.8527 * 1 + -241.0244 * MSSubClass + -143.716 * LotFrontage + … * …
Here, the input house features such as MSSubClass or LotFrontage are represented as x variables. The learnable model parameters (θ) are set with values like -490130.8527 or -241.0244, which have been gained during the training process.
This example uses a simple machine learning algorithm, which requires just a few model parameters. A more complex algorithm, such as for a deep neural network, could require millions of model parameters; that is one of the main reasons why the process of training such algorithms requires high computation power.
The predict() method
Once you have finished training the model, you can use the predict() method to determine the estimated sale price of a house. This method consumes data about house features and produces an estimated sale price. In practice, an agent of a real estate company could enter features such as the size of a lot (lot-area), the number of rooms, or the overall house quality in order to receive an estimated sale price for a given house.
Transforming non-numeric values
You will often be faced with datasets that contain non-numeric values. For instance, the Ames Housing dataset used for the Kaggle House Prices competition includes both numeric and textual listings of house features:
 IDG
IDGFigure 5. A sample from the Kaggle House Prices dataset
To make things more complicated, the Kaggle dataset also includes empty values (marked NA), which cannot be processed by the linear regression algorithm shown in Listing 1.
Real-world data records are often incomplete, inconsistent, lacking in desired behaviors or trends, and may contain errors. This typically occurs in cases where the input data has been joined using different sources. Input data must be converted into a clean data set before being fed into a model.
To improve the data, you would need to replace the missing (NA) numeric LotFrontage value. You would also need to replace textual values such as MSZoning “RL” or “RM” with numeric values. These transformations are necessary to convert the raw data into a syntactically correct format that can be processed by your model.
Once you’ve converted your data to a generally readable format, you may still need to make additional changes to improve the quality of input data. For instance, you might remove values not following the general trend of the data, or place infrequently occurring categories into a single umbrella category.
Java-based machine learning with Weka
As you’ve seen, developing and testing a target function requires well-tuned configuration parameters, such as the proper learning rate or iteration count. The example code you’ve seen so far reflects a very small set of the possible configuration parameters, and the examples were simplified to keep the code readable. In practice, you will likely rely on machine learning frameworks, libraries, and tools.
Most frameworks or libraries implement an extensive collection of machine learning algorithms. Additionally, they provide convenient high-level APIs to train, validate, and process data models. Weka is one of the most popular frameworks for the JVM.
Weka provides a Java library for programmatic usage, as well as a graphical workbench to train and validate data models. In the code below, the Weka library is used to create a training data set, which includes features and a label. The setClassIndex() method is used to mark the label column. In Weka, the label is defined as a class:
// define the feature and label attributes
ArrayList<Attribute> attributes = new ArrayList<>();
Attribute sizeAttribute = new Attribute("sizeFeature");
attributes.add(sizeAttribute);
Attribute squaredSizeAttribute = new Attribute("squaredSizeFeature");
attributes.add(squaredSizeAttribute);
Attribute priceAttribute = new Attribute("priceLabel");
attributes.add(priceAttribute);
// create and fill the features list with 5000 examples
Instances trainingDataset = new Instances("trainData", attributes, 5000);
trainingDataset.setClassIndex(trainingSet.numAttributes() - 1);
Instance instance = new DenseInstance(3);
instance.setValue(sizeAttribute, 90.0);
instance.setValue(squaredSizeAttribute, Math.pow(90.0, 2));
instance.setValue(priceAttribute, 249.0);
trainingDataset.add(instance);
Instance instance = new DenseInstance(3);
instance.setValue(sizeAttribute, 101.0);
...
The data set or Instance object can also be stored and loaded as a file. Weka uses an ARFF (Attribute Relation File Format), which is supported by the graphical Weka workbench. This data set is used to train the target function, known as a classifier in Weka.
Recall that in order to train a target function, you have to first choose the machine learning algorithm. The code below creates an instance of the LinearRegression classifier. This classifier is trained by calling the buildClassifier() method. The buildClassifier() method tunes the theta parameters based on the training data to find the best-fitting model. Using Weka, you do not have to worry about setting a learning rate or iteration count. Weka also does the feature scaling internally:
Classifier targetFunction = new LinearRegression();
targetFunction.buildClassifier(trainingDataset);
Once it’s established, the target function can be used to predict the price of a house, as shown here:
Instances unlabeledInstances = new Instances("predictionset", attributes, 1);
unlabeledInstances.setClassIndex(trainingSet.numAttributes() - 1);
Instance unlabeled = new DenseInstance(3);
unlabeled.setValue(sizeAttribute, 1330.0);
unlabeled.setValue(squaredSizeAttribute, Math.pow(1330.0, 2));
unlabeledInstances.add(unlabeled);
double prediction = targetFunction.classifyInstance(unlabeledInstances.get(0));
Weka provides an Evaluation class to validate the trained classifier or model. In the code below, a dedicated validation data set is used to avoid biased results. Measures such as the cost or error rate will be printed to the console. Typically, evaluation results are used to compare models that have been trained using different machine-learning algorithms, or a variant of these:
Evaluation evaluation = new Evaluation(trainingDataset);
evaluation.evaluateModel(targetFunction, validationDataset);
System.out.println(evaluation.toSummaryString("Results", false));
The examples above use linear regression, which predicts a numeric-valued output such as a house price based on input values. Linear regression supports the prediction of continuous, numeric values. To predict binary yes/no values or classifiers, you could use a machine learning algorithm such as decision tree, neural network, or logistic regression:
// using logistic regression
Classifier targetFunction = new Logistic();
targetFunction.buildClassifier(trainingSet);










{kind=link}