Vertex AI Studio is an online environment for building AI apps, featuring Gemini, Google’s own multimodal generative AI model that can work with text, code, audio, images, and video. In addition to Gemini, Vertex AI provides access to more than 40 proprietary models and more than 60 open source models in its Model Garden, for example the proprietary PaLM 2, Imagen, and Codey models from Google Research, open source models like Llama 2 from Meta, and Claude 2 and Claude 3 from Anthropic. Vertex AI also offers pre-trained APIs for speech, natural language, translation, and vision.
Vertex AI supports prompt engineering, hyper-parameter tuning, retrieval-augmented generation (RAG), and model tuning. You can tune foundation models with your own data, using tuning options such as adapter tuning and reinforcement learning from human feedback (RLHF), or perform style and subject tuning for image generation.
Vertex AI Extensions connect models to real-world data and real-time actions. Vertex AI allows you to work with models both in the Google Cloud console and via APIs in Python, Node.js, Java, and Go.
Competitive products include Amazon Bedrock, Azure AI Studio, LangChain/LangSmith, LlamaIndex, Poe, and the ChatGPT GPT Builder. The technical levels, scope, and programming language support of these products vary.
Vertex AI Studio
Vertex AI Studio is a Google Cloud console tool for building and testing generative AI models. It allows you to design and test prompts and customize foundation models to meet your application’s needs.
Foundation models are another term for the generative AI models found in Vertex AI. Calling them foundation models emphasizes the fact that they can be customized with your data for the specialized purposes of your application. They can generate text, chat, image, code, video, multimodal data, and embeddings.
Embeddings are vector representations of other data, for example text. Search engines often use vector embeddings, a cosine metric, and a nearest-neighbor algorithm to find text that is relevant (similar) to a query string.
The proprietary Google generative AI models available in Vertex AI include:
- Gemini API: Advanced reasoning, multi-turn chat, code generation, and multimodal prompts.
- PaLM API: Natural language tasks, text embeddings, and multi-turn chat.
- Codey APIs: Code generation, code completion, and code chat.
- Imagen API: Image generation, image editing, and visual captioning.
- MedLM: Medical question answering and summarization (private GA).
Vertex AI Studio allows you to test models using prompt samples. The prompt galleries are organized by the type of model (multimodal, text, vision, or speech) and the task being demonstrated, for example “summarize key insights from a financial report table” (text) or “read the text from this handwritten note image” (multimodal).
Vertex AI also helps you to design and save your own prompts. The types of prompt are broken down by purpose, for example text generation versus code generation and single-shot versus chat. Iterating on your prompts is a surprisingly powerful way of customizing a model to produce the output you want, as we’ll discuss below.
When prompt engineering isn’t enough to coax a model into producing the desired output, and you have a training data set in a suitable format, you can take the next step and tune a foundation model in one of several ways: supervised tuning, RLHF tuning, or distillation. Again, we’ll discuss this in more detail later on in this review.
The Vertex AI Studio speech tool can convert speech to text and text to speech. For text to speech you can choose your preferred voice and control its speed. For speech to text, Vertex AI Studio uses the Chirp model, but has length and file format limits. You can circumvent those by using the Cloud Speech-to-Text Console instead.
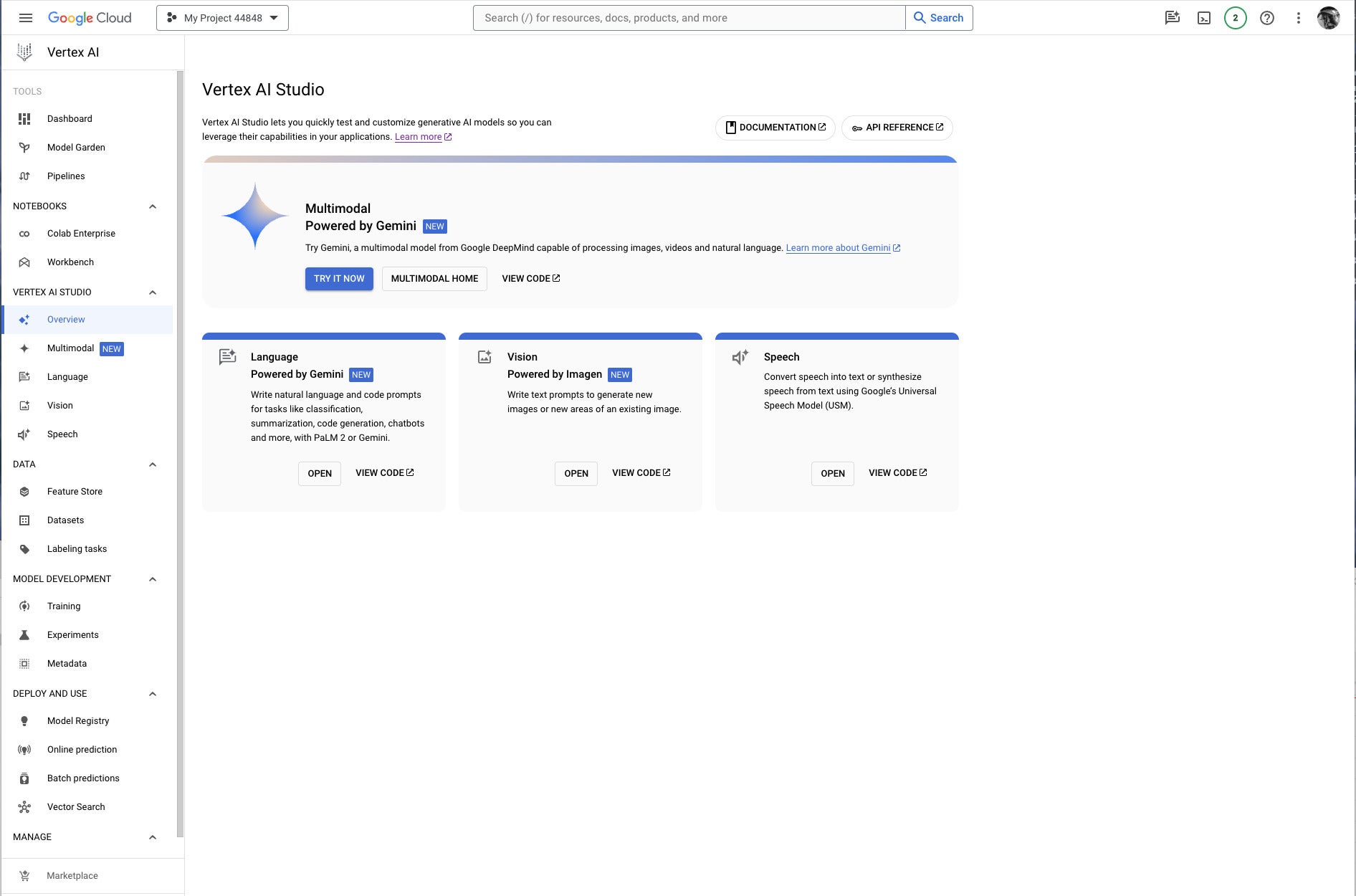 IDG
IDGGoogle Vertex AI Studio overview console, emphasizing Google’s newest proprietary generative AI models. Note the use of Google Gemini for multimodal AI, PaLM2 or Gemini for language AI, Imagen for vision (image generation and infill), and the Universal Speech Model for speech recognition and synthesis.
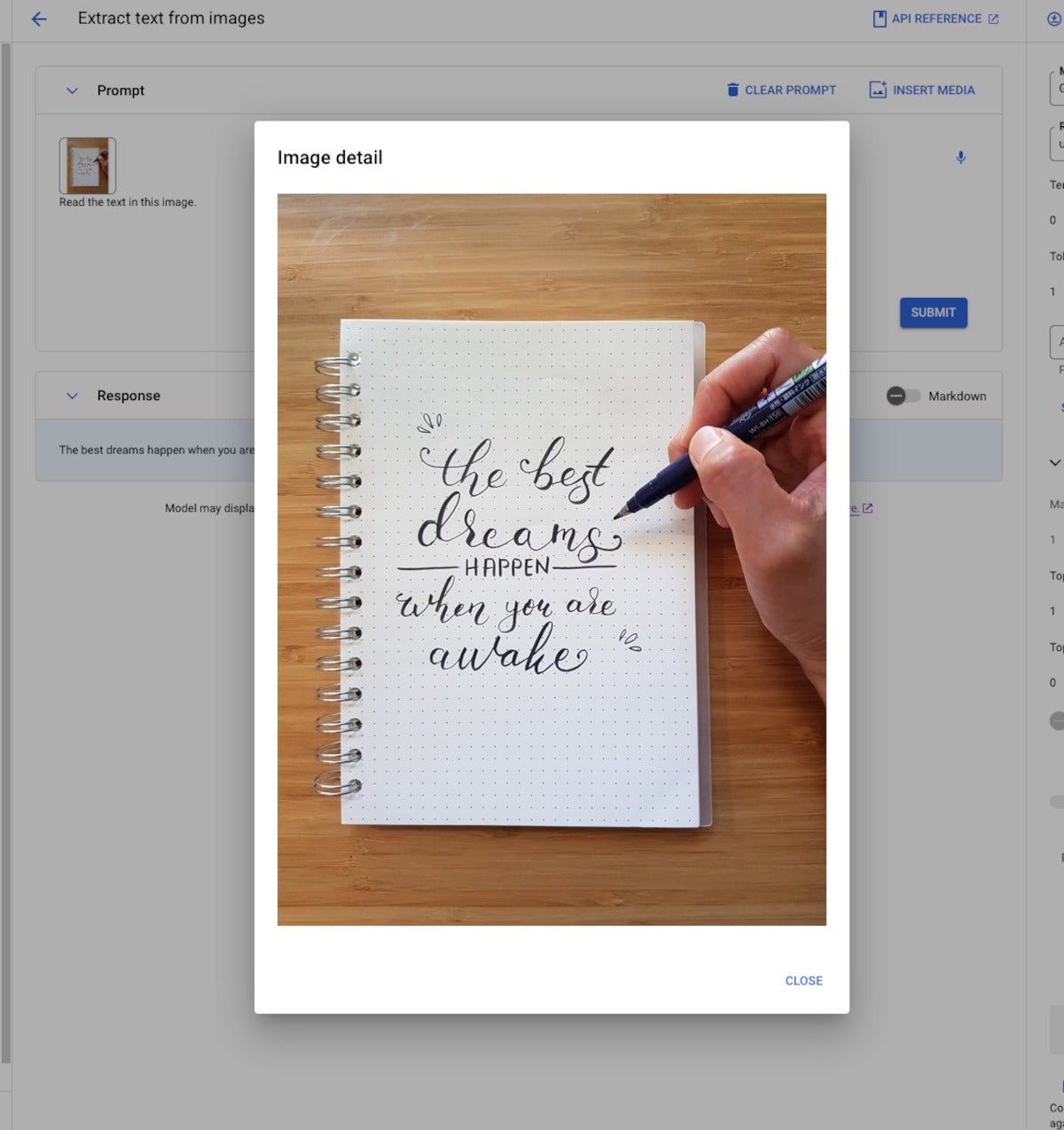 IDG
IDGMultimodal generative AI demonstration from Vertex AI. The model, Gemini Pro Vision, is able to read the message from the image despite the elaborate calligraphy.
Generative AI workflow
As you can see in the diagram below, Google Vertex AI’s generative AI workflow is a bit more complicated than simply throwing a prompt over the wall and getting a response back. Google’s responsible AI and safety filter applies both to the input and output, shielding the model from malicious prompts and the user from malicious responses.
The foundation model that processes the query can be pre-trained or tuned. Model tuning, if desired, can be performed using several methods, all of which are out-of-band for the query/response workflow and quite time-consuming.
If grounding is required, it’s applied here. The diagram shows the grounding service after the model in the flow; that’s not exactly how RAG works, as I explained in January. Out-of-band, you build your vector database. In-band, you generate an embedding vector for the query, use it to perform a similarity search against the vector database, and finally you include what you’ve retrieved from the vector database as an augmentation to the original query and pass it to the model.
At this point, the model generates answers, possibly based on multiple documents. The workflow allows for the inclusion of citations before sending the response back to the user through the safety filter.
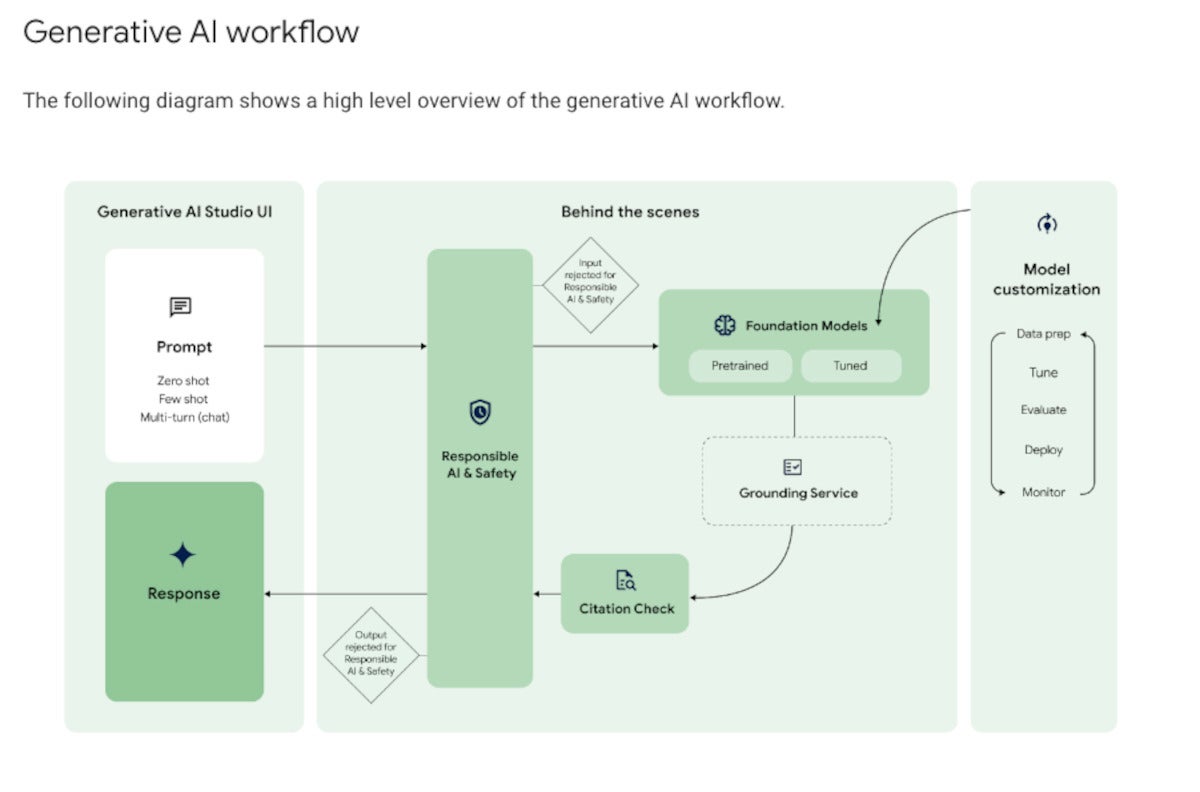 IDG
IDGThe generative AI workflow typically starts with prompting by the user. On the back end, the prompt passes through a safety filter to pre-trained or tuned foundation models, optionally using a grounding service for RAG. After a citation check, the reply passes back through the safety filter and to the user.
Grounding and Vertex AI Search
As you might expect from the way RAG works, Vertex AI requires you to take a few steps to enable RAG. First, you need to “onboard to Vertex AI Search and Conversation,” a matter of a few clicks and a few minutes of waiting. Then you need to create an AI Search data store, which can be accomplished by crawling websites, importing data from a BigQuery table, importing data from a Cloud Storage bucket (PDF, HTML, TXT, JSONL, CSV, DOCX, or PPTX formats), or by calling an API.
Finally, you need to set up a prompt with a model that supports RAG (currently only text-bison and chat-bison, both PaLM 2 language models) and configure it to use your AI Search and Conversation data store. If you are using the Vertex AI console, this setup is in the advanced section of the prompt parameters, as shown in the first screenshot below. If you are using the Vertex AI API, this setup is in the groundingConfig section of the parameters:
{
"instances": [
{ "prompt": "PROMPT"}
],
"parameters": {
"temperature": TEMPERATURE,
"maxOutputTokens": MAX_OUTPUT_TOKENS,
"topP": TOP_P,
"topK": TOP_K,
"groundingConfig": {
"sources": [
{
"type": "VERTEX_AI_SEARCH",
"vertexAiSearchDatastore": "VERTEX_AI_SEARCH_DATA_STORE"
}
]
}
}
}
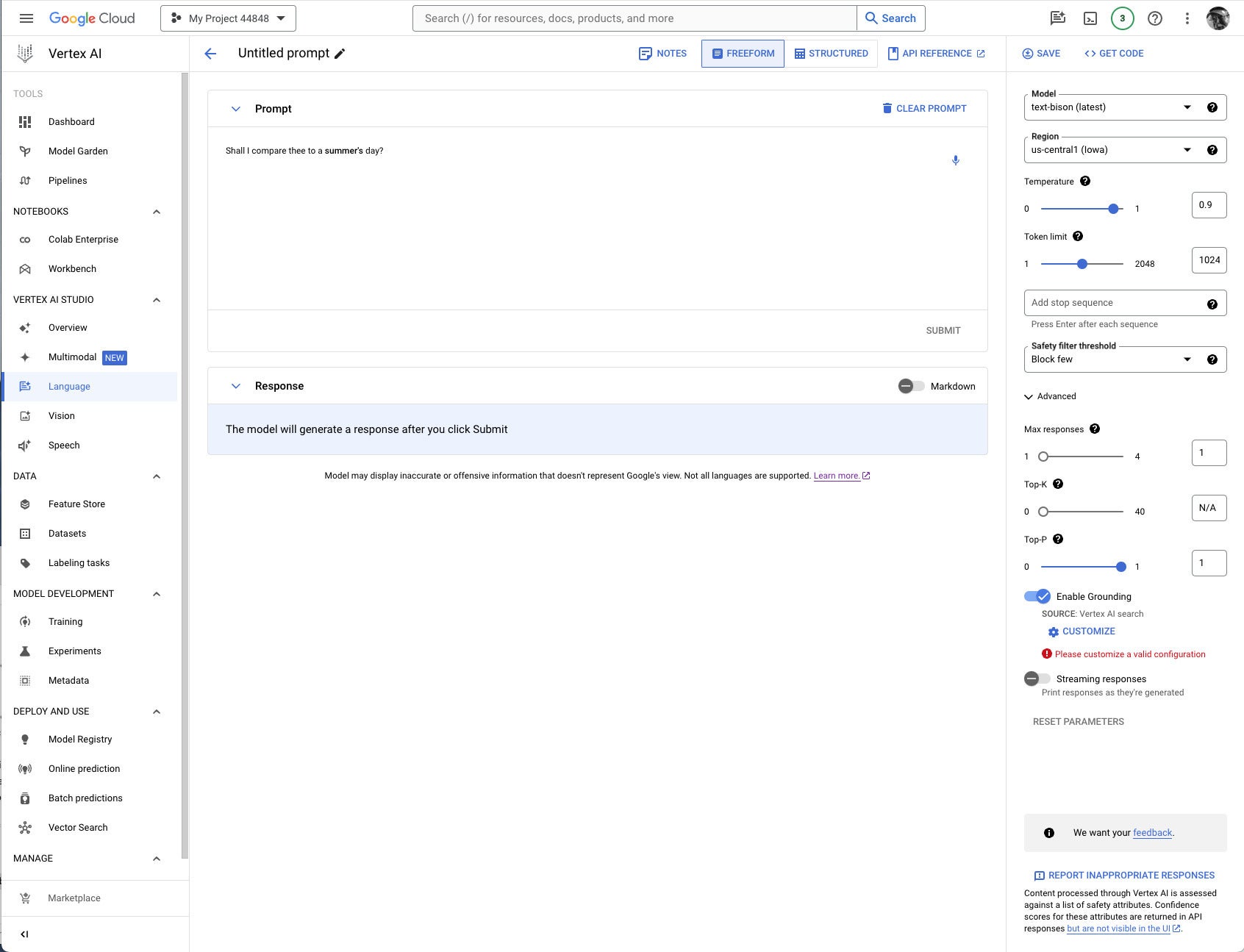 IDG
IDGIf you’re constructing a prompt for a model that supports grounding, the Enable Grounding toggle at the right, under Advanced, will be enabled, and you can click it, as I have here. Clicking on Customize brings up another right-hand panel where you can select Vertex AI Search from the drop-down list and fill in the path to the Vertex AI data store.
Note that grounding or RAG may or may not be needed, depending on how and when the model was trained.
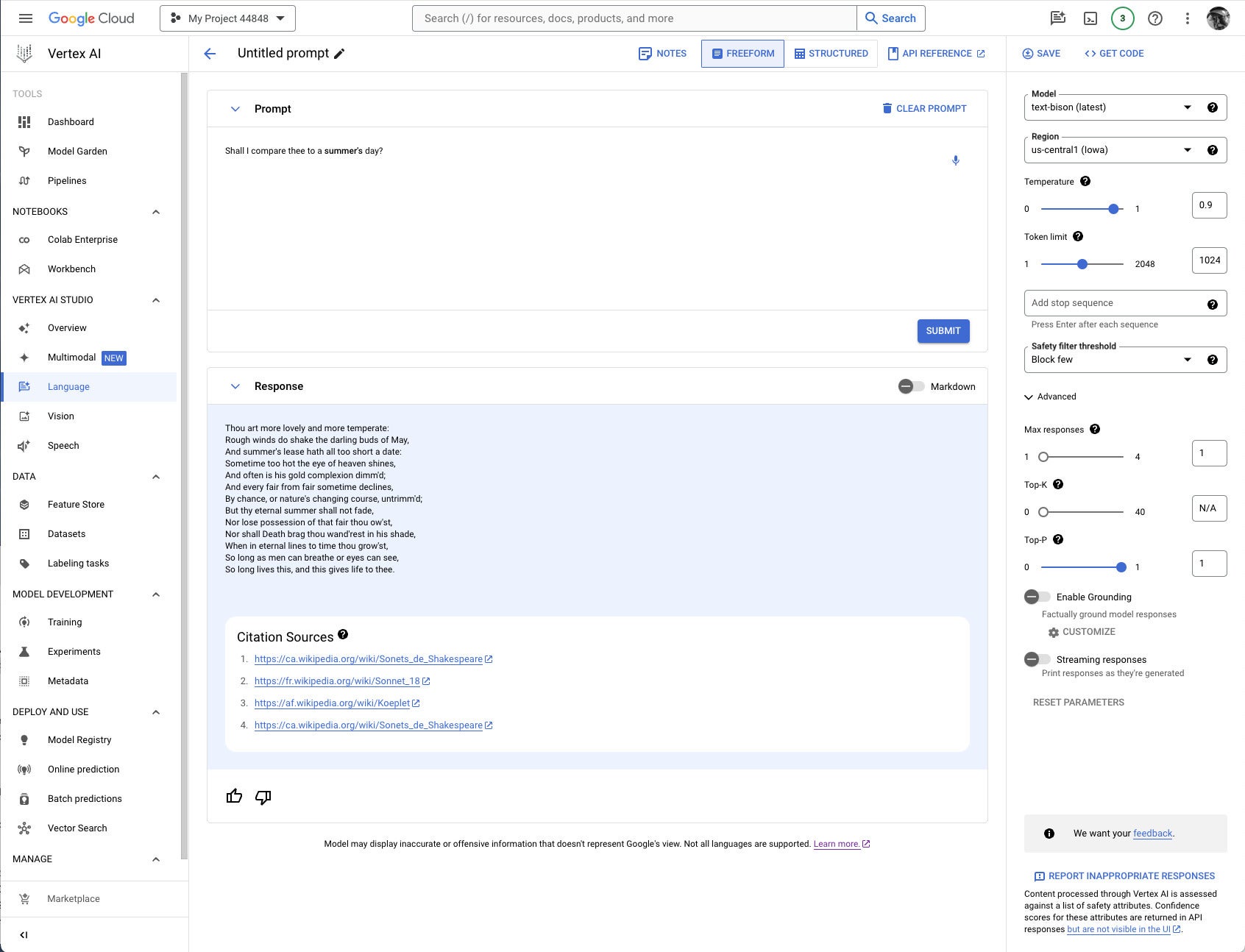 IDG
IDGIt’s usually worth checking to see whether you need grounding for any given prompt/model pair. I thought I might need to add the poems section of the Poetry.org site to get a good completion for “Shall I compare thee to a summer’s day?” But as you can see above, the text-bison model already knew the sonnet from four sources it could (and did) cite.
Gemini, Imagen, Chirp, Codey, and PaLM 2
Google’s proprietary models offer some of the added value of the Vertex AI site. Gemini was unique in being a multimodal model (as well as a text and code generation model) as recently as a few weeks before I wrote this. Then OpenAI GPT-4 incorporated DALL-E, which allowed it to generate text or images. Currently, Gemini can generate text from images and videos, but GPT-4/DALL-E can’t.
Gemini versions currently offered on Vertex AI include Gemini Pro, a language model with “the best performing Gemini model with features for a wide range of tasks;” Gemini Pro Vision, a multimodal model “created from the ground up to be multimodal (text, images, videos) and to scale across a wide range of tasks;” and Gemma, “open checkpoint variants of Google DeepMind’s Gemini model suited for a variety of text generation tasks.”
Additional Gemini versions have been announced: Gemini 1.0 Ultra, Gemini Nano (to run on devices), and Gemini 1.5 Pro, a mixture-of-experts (MoE) mid-size multimodal model, optimized for scaling across a wide range of tasks, that performs at a similar level to Gemini 1.0 Ultra. According to Demis Hassabis, CEO and co-founder of Google DeepMind, Gemini 1.5 Pro comes with a standard 128,000 token context window, but a limited group of customers can try it with a context window of up to 1 million tokens via Vertex AI in private preview.
Imagen 2 is a text-to-image diffusion model from Google Brain Research that Google says has “an unprecedented degree of photorealism and a deep level of language understanding.” It’s competitive with DALL-E 3, Midjourney 6, and Adobe Firefly 2, among others.
Chirp is a version of a Universal Speech Model that has over 2B parameters and can transcribe in over 100 languages in a single model. It can turn audio speech to formatted text, caption videos for subtitles, and transcribe audio content for entity extraction and content classification.
Codey exists in versions for code completion (code-gecko), code generation (̉code-bison), and code chat (codechat-bison). The Codey APIs support the Go, GoogleSQL, Java, JavaScript, Python, and TypeScript languages, and Google Cloud CLI, Kubernetes Resource Model (KRM), and Terraform infrastructure as code. Codey competes with GitHub Copilot, StarCoder 2, CodeLlama, LocalLlama, DeepSeekCoder, CodeT5+, CodeBERT, CodeWhisperer, Bard, and various other LLMs that have been fine-tuned on code such as OpenAI Codex, Tabnine, and ChatGPTCoding.
PaLM 2 exists in versions for text (text-bison and text-unicorn), chat (̉chat-bison), and security-specific tasks (sec-palm, currently only available by invitation). PaLM 2 text-bison is good for summarization, question answering, classification, sentiment analysis, and entity extraction. PaLM 2 chat-bison is fine-tuned to conduct natural conversation, for example to perform customer service and technical support or serve as a conversational assistant for websites. PaLM 2 text-unicorn, the largest model in the PaLM family, excels at complex tasks such as coding and chain-of-thought (CoT).
Google also provides embedding models for text (textembedding-gecko and textembedding-gecko-multilingual) and multimodal (multimodalembedding). Embeddings plus a vector database (Vertex AI Search) allow you to implement semantic or similarity search and RAG, as described above.
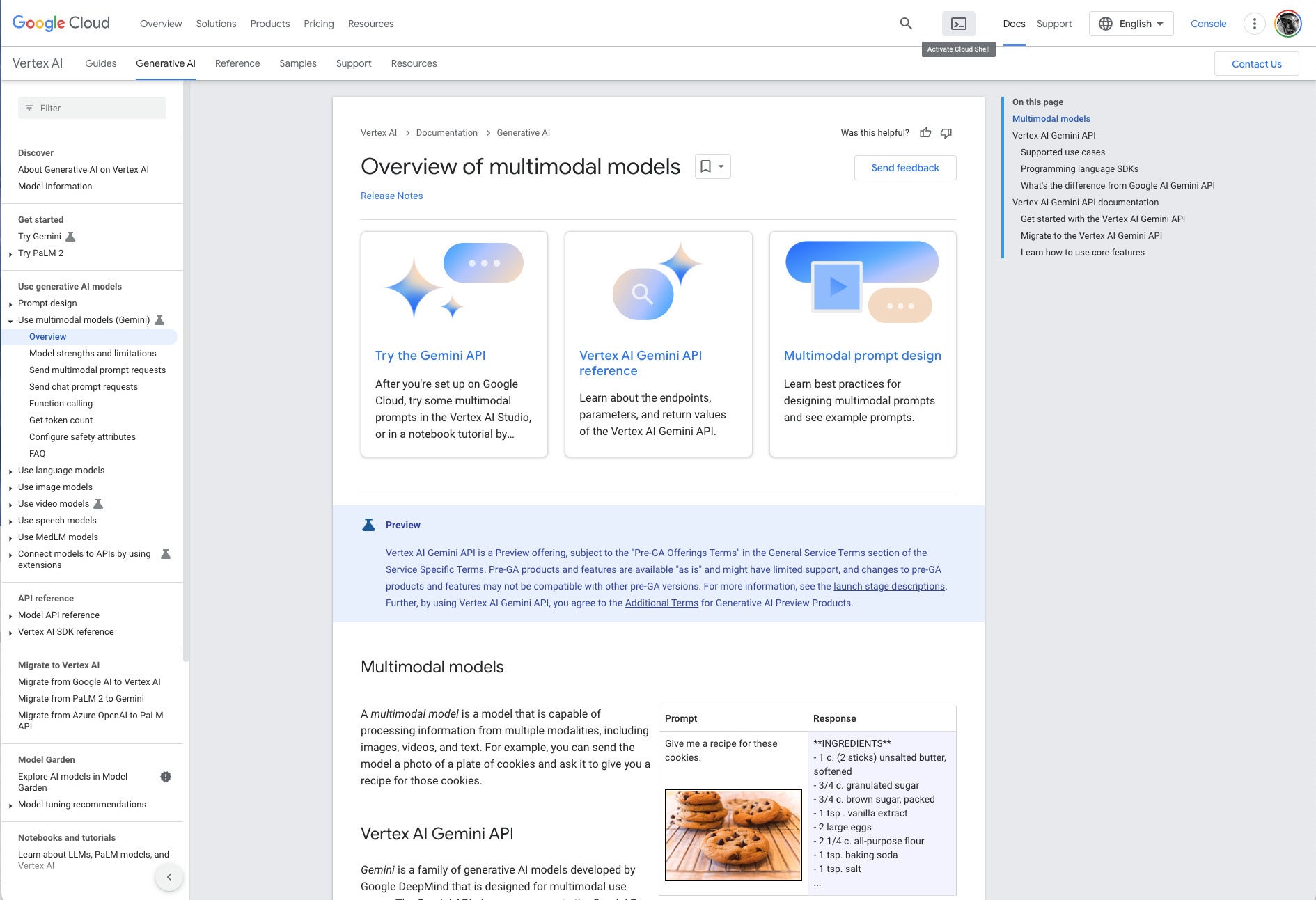 IDG
IDGVertex AI documentation overview of multimodal models. Note the example at the lower right. The text prompt “Give me a recipe for these cookies” and an unlabeled picture of chocolate-chip cookies causes Gemini to respond with an actual recipe for chocolate-chip cookies.
Vertex AI Model Garden
In addition to Google’s proprietary models, the Model Garden (documentation) currently offers roughly 90 open-source models and 38 task-specific solutions. In general, the models have model cards. The Google models are available through Vertex AI APIs and Google Colab as well as in the Vertex AI console. The APIs are billed on a usage basis.
The other models are typically available in Colab Enterprise and can be deployed as an endpoint. Note that endpoints are deployed on serious instances with accelerators (for example 96 CPUs and 8 GPUs), and therefore accrue significant charges as long as they are deployed.
Foundation models offered include Claude 3 Opus (coming soon), Claude 3 Sonnet (preview), Claude 3 Haiku (coming soon), Llama 2, and Stable Diffusion v1-5. Fine-tunable models include PyTorch-ZipNeRF for 3D reconstruction, AutoGluon for tabular data, Stable Diffusion LoRA (MediaPipe) for text to image generation, and ̉̉MoViNet Video Action Recognition.
Generative AI prompt design
The Google AI prompt design strategies page does a decent and generally vendor-neutral job of explaining how to design prompts for generative AI. It emphasizes clarity, specificity, including examples (few-shot learning), adding contextual information, using prefixes for clarity, letting models complete partial inputs, breaking down complex prompts into simpler components, and experimenting with different parameter values to optimize results.
Let’s look at three examples, one each for multimodal, text, and vision. The multimodal example is interesting because it uses two images and a text question to get an answer.









{kind=link}