REST, or Representational State Transfer, is the ubiquitous architectural style that answers the pivotal question: how will web servers and clients communicate? Of all the acronyms floating around the world of software engineering, REST is one of the most common. It is also one of the most frequently misunderstood. This article offers a quick guide to REST in both theory and practice. In other words, we’ll look at both the theory of REST and how it is actually implemented, which is mostly in the form of RESTful APIs.
REST in theory
Building software to be distributed on the Internet entails an inherent degree of complexity. The TCP/IP and HTTP stack gives us a basic mechanism for exchanging data over the wire, but the protocols end there. Software developers have had to devise our own higher-level approaches for organizing how resources will be packaged and distributed via web applications.
In this introduction to REST, Roy Fielding started with a comprehensive description of the strengths and weaknesses of various web architectures at the turn of the century. He concluded that the complexity of networked systems was hard to manage, and that developers needed a way to preserve beneficial traits like scalability, reliability, and performance without sacrificing simplicity.
Fielding then proposed REST as an architectural solution to the complexity of distributing software over the Internet. A high-level summary of his proposal might be: components should transmit their internal state in a standard, implementation-agnostic format. Said differently, a web architecture should be comprised of decoupled components that communicated by a standard protocol. This was simply good design, albeit applied to a large problem space. But Fielding had something more specific in mind:
The name “Representational State Transfer” is intended to evoke an image of how a well-designed Web application behaves: a network of web pages (a virtual state-machine), where the user progresses through the application by selecting links (state transitions), resulting in the next page (representing the next state of the application) being transferred to the user and rendered for their use.
You’ll notice the prominence of web pages and links in that description. REST originally referred to hypermedia (especially HTML) and hyperlinks. Essentially, a web service hosts resources at various URLs and URIs. When a user calls a resource, the service responds with an HTML page. The page contains links that can be used to navigate to other resources, and so the process continues. This vision supports many of the goals of good software design: uniform interfaces, stateless components, cacheable resources, and services that can be composed or layered.
RESTful APIs
These days, the most common approach to REST doesn’t work the way it was originally conceived. Instead, developers typically use an HTTP API and JSON to distribute software on the web. That’s why you’ll often hear a so-called REST architecture described as RESTful—as in, something similar to REST.
In the RESTful style, a client requests a resource using a conventionally formatted URL (a RESTful API) and receives back a conventionally formatted JSON response, which describes the resource using key/value pairs.
The conventional URL and JSON responses are the distinctive characteristics of modern RESTful web applications. In this style, the URL path describes where an asset exists and the HTTP verb describes how to manipulate it. For example, if you have an API that contains data about music, you might have an endpoint URL like musicservice/albums/1234, where 1234 is the ID of a given asset. If you issue a GET request on that endpoint, you’ll get back a JSON document for that asset, something like this:
Listing 1. A simple RESTful service
Response:
{
id: 1234,
name: “Abbey Road”,
band: “The Beatles”,
year: 1969,
best_song: “Come Together”
}
In Listing 1, you see that the endpoint responds with data that describes the asset. This respects the requirement that the service not reveal anything about implementation. The other verbs allow you to delete the resource (HTTP DELETE) , modify it (HTTP PUT), or create a new one (HTTP POST).
The structure of the API is not rigid. The main rule is that GET requests should not change anything (in other words, GET is idempotent). Often, a GET request to the musicservice/albums endpoint would return a list of albums. The endpoint would also support filter and/or query parameters as part of the URL, like this one:
musicservice/albums?band_name=”pink_floyd”&years=”1973-1980”&sort=alpha
As the API grows more complex, the representation of resources becomes less consistent. Let’s say our MusicService API supports tagging albums according to style or genre. You could associate a tag to an album or an album to a tag. In many cases, the approach in a RESTful API boils down to style and preference. The rule that matters most is: be as consistent as possible. You want the URL syntax to be consistent so that it’s easy for someone writing code to the API to do their task.
When you see a discussion of REST these days, it usually means RESTful design. Clients are written in JavaScript using one of many available frameworks. Ajax-style requests are often used to drive fine-grained interactions in single-page applications. Services (up to and including microservices) are written using all kinds of tech stacks because they issue standardized formats. Services written in this style can interact with each other to fulfill requests in a consistent and interoperable way.
Rest vs. SOAP
REST in theory is a kind of self-describing service architecture, where clients understand what the standards are and the service emits data that conforms to those standards. The client can more or less proceed without knowing anything about the service structure. On the other end of the spectrum is a style of client-service relationship called Remote Procedure Call, or RPC. In this model, the client and server create a formal contract that specifies the exact nature of their interactions. They then relate in a similar mode as procedure calls in local code. RPC maps the function calls of normal code onto network calls.
RPC has some advantages in that it is more rigorous and lends itself to planning and well-defined services and clients. The downside of RPC is its rigidity. Whenever a client or server changes, the other has to change too, and so does the mechanism that defines the contract.
RPC and SOAP
The most famous example of RPC is probably SOAP (Simple Object Access Protocol). In this system, clients and servers use XML definitions to describe their contracts. SOAP was a big part of the SOA (service-oriented architecture) movement at the turn of the century. In this model, services expose service definitions and clients can parse these to discover capabilities. This idea didn’t really work out, however, mainly due to the burden of complexity. SOA and SOAP added too much overhead to the already complex work developers had to do. (See Intro to gRPC: The REST alternative for an overview of the more modern approach to RPC.)
REST in theory dispenses with unique contracts between clients and servers by letting the service emit data in a format that describes itself. This makes for more flexibility while preserving capability (the genius of the Fielding paper).
REST as practiced is more of a natural in-between point. Where RPC and SOA use formal client-server contracts, REST and REST-like JSON do not. Where REST decouples clients and servers (with limited foreknowledge of service on the client), REST-like clients are coupled to the server (they have foreknowledge of the service). Figure 1 shows the difference between the two architectures.
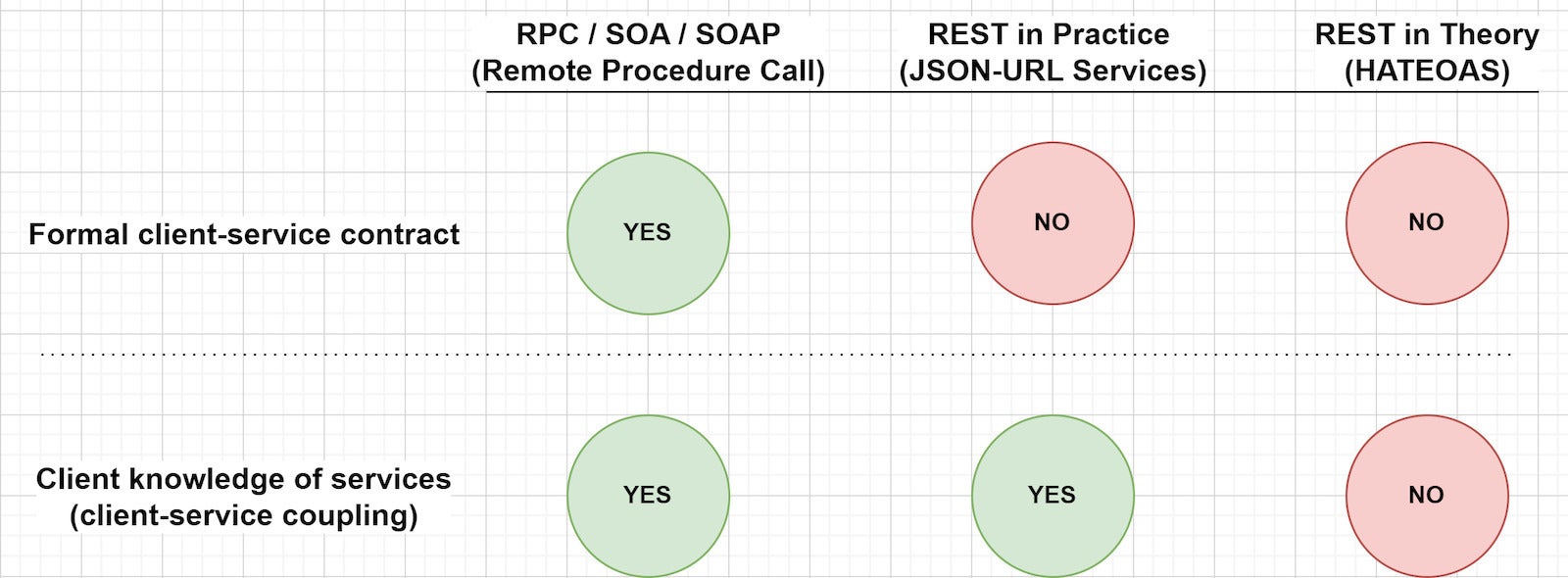 IDG
IDGFigure 1. REST decouples clients and servers, but REST-like clients are coupled to the server.
When we say REST clients lack foreknowledge of the service, we mean they don’t know the specifics. They may and probably do know more about the standard structures and assumptions in use.
REST-like services (that is, JSON-URL services) actually maximize the speed of development. In that way, it’s no surprise that this model has found the greatest traction for real-world use.
What about HATEOAS?
The downside of the REST-like approach is that it tends toward complexity. In this, it diverges from Roy Fielding’s vision for REST. The complexity of RESTful design is most obviously seen in the sophistication of modern web clients, which must be able to receive JSON and dynamically transform it into interactive user interfaces.
The issue here is that most developers implementing REST as an architectural style have abandoned one of its original pillars—the HATEOAS principle. That oddly unappealing acronym stands for Hypermedia as the Engine of Application State. Essentially, it means that we should only issue hypermedia from services—an idea that is directly opposed to issuing JSON as the means of distribution. Fielding calls this principle the hypermedia constraint, and he’s been vocal about pointing out its widespread violation:
A REST API must not define fixed resource names or hierarchies (an obvious coupling of client and server). Servers must have the freedom to control their own namespace. Instead, allow servers to instruct clients on how to construct appropriate URIs, such as is done in HTML forms and URI templates, by defining those instructions within media types and link relations. [Failure here implies that clients are assuming a resource structure due to out-of band information, such as a domain-specific standard, which is the data-oriented equivalent to RPC’s functional coupling.]
Clearly, most RESTful APIs ignore this essential aspect of the REST style, where clients are meant to simply follow the output from services—including all the data required to interact with the services. The essence of hypermedia is that it describes both the assets and how to navigate them. (Carson Gross, creator of HTMX, recently took on this issue with his blog post, How did REST come to mean the opposite of REST?. It’s worth a read.)
Conclusion
Criticisms of the RESTful style versus the originally intended design of REST are valid. Maintaining JSON/HTTP services is tough, and REST-as-intended might hold out some hope for improvements. At the same time, the real-world use remains JSON responses based on RPC-like URL structures. This style has the advantage of common use, wide implementation, and semantics that are easily understood.
Every working web developer today is required to understand both the basic principles of REST (the theory) and how they are widely applied in RESTful applications and interfaces (the practice). Both are worth considering as we continue to build this Internet plane while we fly it.
Copyright © 2023 IDG Communications, Inc.










{kind=link}